IPC in Rust
At work, our team recently found ourselves in need of a high-performance IPC solution in Rust. Our search led us to an insightful article by 3tilley, "IPC in Rust - a Ping Pong Comparison," which provided a great starting point for our exploration.
Inspired by this work, we decided to dive deeper and conduct our own performance measurements, with a particular interest in the promising iceoryx2 framework. Building on the work presented in the original article, we will be using UNIX Domain Sockets (both stream and datagram), Memory Mapped Files, and Shared Memory using iceoryx2 crate to explore the IPC performance between processes running on the same machine for varying payload sizes.
Setup
We will measure the time taken to complete a request-response cycle between two processes communicating over IPC. All the experiments are setup similar to the original work,
- A producer process sends a request payload of size
𝑥KB - A consumer process responds with a payload of same size
𝑥KB - We measure the round-trip time for this exchange
and we will be using the same benchmarking tool Divan.
Hardware and OS
- Env: Linux Cloud VM
- Arch: x86_64
- CPU: 32 cores
- Model Name: AMD EPYC 7B13
- L1d cache: 512 KiB
- L1i cache: 512 KiB
- L2 cache: 8 MiB
- L3 cache: 64 MiB
- Memory: 128GB
- OS: Ubuntu 20.04.1
- Kernel: 5.15.0
Optimization and Measurement Techniques
- CPU Affinity: Tying the processes to specific cores prevents process migration between cores, which can introduce variability in measurements due to context switching overhead. Used core_affinity crate for this.
- CPU Warmup: To account for initial low power states and ensure consistent CPU frequency, we have implemented a 1-second warmup period before taking measurements. This allows the CPU to reach its steady-state performance, providing more accurate and consistent results across different IPC mechanisms.
pub fn cpu_warmup() {
let warmup = std::time::Instant::now();
loop {
if warmup.elapsed() > std::time::Duration::from_millis(1000) {
break;
}
}
}
Payload Generation
The paylaods are randomly generated Strings conataining alphanumeric characters.
pub fn generate_random_data(data_size: usize, seed: u64) -> Vec<u8> {
const CHARSET: &[u8] = b"ABCDEFGHIJKLMNOPQRSTUVWXYZ\
abcdefghijklmnopqrstuvwxyz\
0123456789";
let mut rng = StdRng::seed_from_u64(seed);
(0..data_size)
.map(|_| {
let idx = rng.gen_range(0..CHARSET.len());
CHARSET[idx]
})
.collect()
}
Since data transmission happens in bytes, we generate strings as byte vectors(Vec<u8>) of given size. seed helps in generating same payloads for a given data_size ensuring data consistency for all the approaches we test.
pub fn get_payload(data_size: usize) -> (Vec<u8>, Vec<u8>) {
let request_data = generate_random_data(data_size, 1);
let response_data = generate_random_data(data_size, 2);
(request_data, response_data)
}
get_payload function returns request data and response data to be transmitted.
Approach 1 - UNIX Domain Stream Socket
UNIX Domain Sockets(UDS) are typically considered a better option if data exchange is needed between processes running on the same UNIX host, compared to IP sockets. They are said to be faster and lighter than IP sockets as they avoid some operations needed for network interface.
Here's a simplified implementation of the UNIX Domain Stream Socket approach:
...
// Producer
const UNIX_SOCKET_PATH: &str = "/tmp/unix_stream.sock";
impl UnixStreamRunner {
pub fn new(start_child: bool, data_size: usize) -> Self {
let unix_listener = UnixListener::bind(UNIX_SOCKET_PATH).unwrap();
let exe = crate::executable_path("unix_stream_consumer");
let child_proc = if start_child {
Some(Command::new(exe).args(&[data_size.to_string()]).spawn().unwrap())
} else {
None
};
let wrapper = UnixStreamWrapper::from_listener(unix_listener);
let (request_data, response_data) = get_payload(data_size);
Self { child_proc, wrapper, data_size, request_data, response_data }
}
pub fn run(&mut self, n: usize) {
let mut buf = vec![0; self.data_size];
for _ in 0..n {
self.wrapper.stream.write(&self.request_data).unwrap();
self.wrapper.stream.read_exact(&mut buf).unwrap();
}
}
}
...
// Cosumer
fn main() {
let args: Vec<String> = std::env::args().collect();
let data_size = usize::from_str(&args[1]).unwrap();
core_affinity::set_for_current(core_affinity::CoreId { id: 0 });
let mut wrapper = ipc::unix_stream::UnixStreamWrapper::unix_connect();
let (request_data, response_data) = get_payload(data_size);
cpu_warmup();
let mut buf = vec![0; data_size];
while let Ok(_) = wrapper.stream.read_exact(&mut buf) {
wrapper.stream.write(&response_data).unwrap();
}
}
For a domain stream socket, we provide path on the file system which will be created and used as the socket's address. After connecting the sockets, request_data is written to the socket and the consumer reads the message into a buffer, then responds with response_message.
Approach 2 - Unix Datagram Socket
While implementing UNIX domain datagram socket, we faced few issues at runtime:
-
"Address already in use": We initially tried to use a single socket path
/tmp/unix_datagram.sockfor the communication, similar to unix stream socket. We tried to bind both processes to the same socket path which lead to "Address already in use" runtime error. Then we found that, for unix domain datagram sockets, we have to bind each process to a separate socket path. For communication between these two sockets, weconnect()each socket to the other which sets the peer address. -
"Message too big": This error is due to the UDP datagram size limitation. UDP has a theoretical maximum datagram size of 65,507 bytes. To handle larger data sizes, we have to send the payload in chunks.
-
"No buffer space available": Upon our search to resolve this error, we found on stackoverflow that this error occurs when the kernel cannot allocate a memory for the socket buffer and it is not possible to send any data over any socket till some memory is freed. We have handled this by implementing a retry mechanism. We keep retrying until we get a successful write.
-
Data Loss: We would need more fine-grained flow control on the UDP side to prevent packet drops for higher payload sizes. As our primary intention is to measure difference between shared memory based IPC and other approaches, we are dropping that exercise for now. To prevent the program from panicking due to occasional data loss or corruption, we have removed the strict data validation checks. This allows the program to continue running even if some packets are lost or arrive out of order.
Here's a simplified implementation:
...
// Producer
const MAX_CHUNK_SIZE: usize = 64 * KB;
const UNIX_DATAGRAM_SOCKET_1: &str = "/tmp/unix_datagram1.sock";
const UNIX_DATAGRAM_SOCKET_2: &str = "/tmp/unix_datagram2.sock";
impl UnixDatagramWrapper {
pub fn new(is_child: bool, data_size: usize) -> Self {
let (socket_path, peer_socket_path) = if is_child {
(UNIX_DATAGRAM_SOCKET_1, UNIX_DATAGRAM_SOCKET_2)
} else {
(UNIX_DATAGRAM_SOCKET_2, UNIX_DATAGRAM_SOCKET_1)
};
let socket = UnixDatagram::bind(socket_path).unwrap();
Self { socket, peer_socket_path, data_size, }
}
pub fn connect_to_peer(&self) {
self.socket.connect(&self.peer_socket_path).unwrap();
}
pub fn send(&self, data: &Vec<u8>) {
// Send data in chunks
for chunk in data.chunks(MAX_CHUNK_SIZE) {
// Retry until we have a successful write
loop {
match self.socket.send(chunk) {
Ok(_) => break,
Err(_) => continue,
}
}
}
}
pub fn recv(&self) -> Vec<u8> {
let mut received_data = Vec::new();
// Read till we receive all chunks
loop {
let mut buf = vec![0; MAX_CHUNK_SIZE];
let size = self.socket.recv(&mut buf).unwrap();
received_data.extend_from_slice(&buf[..size]);
if received_data.len() == self.data_size {
break;
}
}
received_data
}
}
impl UnixDatagramRunner {
pub fn new(start_child: bool, data_size: usize) -> Self {
let is_child = false;
let wrapper = UnixDatagramWrapper::new(is_child, data_size);
let (request_data, response_data) = get_payload(data_size);
let exe = crate::executable_path("unix_datagram_consumer");
let child_proc = if start_child {
Some(Command::new(exe).args(&[data_size.to_string()]).spawn().unwrap(),)
} else {
None
};
// Awkward sleep to make sure the child proc is ready
sleep(Duration::from_millis(500));
wrapper.connect_to_peer();
Self { child_proc, wrapper, request_data, response_data, }
}
pub fn run(&mut self, n: usize, print: bool) {
let start = Instant::now();
for _ in 0..n {
self.wrapper.send(&self.request_data);
let _response = self.wrapper.recv();
}
}
}
...
// Consumer
fn main() {
let args: Vec<String> = std::env::args().collect();
let data_size = usize::from_str(&args[1]).unwrap();
core_affinity::set_for_current(core_affinity::CoreId { id: 0 });
let is_child = true;
let socket_wrapper = ipc::unix_datagram::UnixDatagramWrapper::new(is_child, data_size);
socket_wrapper.connect_to_peer();
let (request_data, response_data) = get_payload(data_size);
cpu_warmup();
loop {
let _request = socket_wrapper.recv();
socket_wrapper.send(&response_data);
}
}
For each process, we bind() sockets to the socket_path and connect each socket to their peer_socket_path. Then we send request_data in chunks and retry until we have successfully sent all data. The child process reads till all the chunks are received and responds with response_data.
Approach 3 - Memory Mapped Files
Memory-mapped files are a method of accessing file contents by mapping them in the virtual address space of the calling process. To make the changes made by one process be visible to the other, we call mmap() with MAP_SHARED flag enabled. The synchronisation between processes has been handled similar to the original work using raw_sync crate.
// Shared memory layout
//| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
//| producer lock | consumer lock | data buffer (ping or pong) |
pub struct MmapWrapper {
pub mmap: MmapMut,
pub owner: bool,
pub our_event: Box<dyn EventImpl>,
pub their_event: Box<dyn EventImpl>,
pub data_start: usize,
pub data_size: usize,
}
impl MmapWrapper {
pub fn new(owner: bool) -> Self {
let path: PathBuf = "/tmp/mmap_data.txt".into();
let file = OpenOptions::new()
.read(true)
.write(true)
.create(true)
.open(&path)
.unwrap();
file.set_len(8).unwrap();
let mut mmap = unsafe { MmapMut::map_mut(&file).unwrap() };
let bytes = mmap.as_mut();
// The two events are locks - one for each side. Each side activates the lock while it's
// writing, and then unlocks when the data can be read
let ((our_event, lock_bytes_ours), (their_event, lock_bytes_theirs)) = unsafe {
if owner {
(
BusyEvent::new(bytes.get_mut(0).unwrap(), true).unwrap(),
BusyEvent::new(bytes.get_mut(2).unwrap(), true).unwrap(),
)
} else {
(
// If we're not the owner, the events have been created already
BusyEvent::from_existing(bytes.get_mut(2).unwrap()).unwrap(),
BusyEvent::from_existing(bytes.get_mut(0).unwrap()).unwrap(),
)
}
};
// Confirm that we've correctly indexed two bytes for each lock
assert!(lock_bytes_ours <= 2);
assert!(lock_bytes_theirs <= 2);
if owner {
our_event.set(EventState::Clear).unwrap();
their_event.set(EventState::Clear).unwrap();
}
Self {
mmap,
owner,
our_event,
their_event,
data_start: 4,
data_size,
}
}
pub fn signal_start(&mut self) {
self.our_event.set(EventState::Clear).unwrap()
}
pub fn signal_finished(&mut self) {
self.our_event.set(EventState::Signaled).unwrap()
}
pub fn write(&mut self, data: &[u8]) {
(&mut self.mmap[self.data_start..]).write(data).unwrap();
}
pub fn read(&self) -> &[u8] {
&self.mmap.as_ref()[self.data_start..self.data_size]
}
}
MmapMut::map_mut() function creates a shared and writeable memory map backed by a file. The First 4 bytes in the memory mapping is reserved for event control and the rest 4 bytes are used to store the data.
pub fn run(&mut self, n: usize, print: bool) {
for _ in 0..n {
// Activate our lock in preparation for writing
self.wrapper.signal_start();
self.wrapper.write(&self.request_data);
// Unlock after writing
self.wrapper.signal_finished();
// Wait for their lock to be released so we can read
if self.wrapper.their_event.wait(Timeout::Infinite).is_ok() {
let str = self.wrapper.read();
}
}
}
We lock, write, unlock and read the data when we are allowed to.
Approach 4 - Shared Memory using iceoryx2
iceoryx2 library provides a zero-copy and lock-free inter-process communication. Currently the library doesn't have support for request-response mechanism, so we will use their publish-subscribe mechanism to measure the request-response cycle response time.
Here is a simplified implementation:
...
// Producer
pub struct IceoryxWrapper {
pub publisher: Publisher<ipc::Service, [u8], ()>,
pub subscriber: Subscriber<ipc::Service, [u8], ()>,
}
impl IceoryxWrapper {
pub fn new(is_producer: bool, data_size: usize) -> IceoryxWrapper {
let node = NodeBuilder::new().create::<ipc::Service>().unwrap();
let request_name = ServiceName::new(&format!("Request")).unwrap();
let request_service = node
.service_builder(&request_name)
.publish_subscribe::<[u8]>()
.open_or_create()
.unwrap();
let response_name = ServiceName::new(&format!("Respose")).unwrap();
let response_service = node
.service_builder(&response_name)
.publish_subscribe::<[u8]>()
.open_or_create()
.unwrap();
let (publisher, subscriber) = if is_producer {
(
request_service
.publisher_builder()
.max_slice_len(data_size)
.create()
.unwrap(),
response_service.subscriber_builder().create().unwrap(),
)
} else {
(
response_service
.publisher_builder()
.max_slice_len(data_size)
.create()
.unwrap(),
request_service.subscriber_builder().create().unwrap(),
)
};
IceoryxWrapper {
publisher,
subscriber,
}
}
}
impl IceoryxRunner {
pub fn run(&mut self, n: usize, print: bool) {
for _ in 0..n {
let sample = self
.wrapper
.publisher
.loan_slice_uninit(self.data_size)
.unwrap();
let sample = sample.write_from_slice(self.request_data.as_slice());
sample.send().unwrap();
// Waiting for response
loop {
if let Some(recv_payload) = self.wrapper.subscriber.receive().unwrap() {
break;
}
}
}
}
}
...
// Consumer
fn main() {
let args: Vec<String> = std::env::args().collect();
let data_size = usize::from_str(&args[1]).unwrap();
core_affinity::set_for_current(core_affinity::CoreId { id: 0 });
let wrapper = ipc::iceoryx::IceoryxWrapper::new(false, data_size);
let (request_data, response_data) = get_payload(data_size);
cpu_warmup();
loop {
if let Some(recv_payload) = wrapper.subscriber.receive().unwrap() {
let sample = wrapper.publisher.loan_slice_uninit(data_size).unwrap();
let sample = sample.write_from_slice(response_data.as_slice());
sample.send().unwrap();
}
}
}
We have defined two publish-subscibe services. One service is used to send the request payload and the other is used to send the response. After request_data is published, the child proccess reads the message by subscribing to the service. Then the child process publishes response_data to the other service which is subscribed and read by the parent process.
Results
Ping-Pong Cycle
| # | Approach | Time per Operation (µs) | Ops per Second | Time Comparison to Shared Memory |
|---|---|---|---|---|
| 1 | stdin_stdout | 16.36 | 62k | 139.1x |
| 2 | tcp_nodelay | 23.45 | 43k | 199.4x |
| 3 | tcp_yesdelay | 21.71 | 46k | 184.6x |
| 4 | udp | 24.02 | 42k | 204.2x |
| 5 | unix_datagram | 17.97 | 56k | 152.8x |
| 6 | unix_stream | 15.54 | 64k | 132.1x |
| 7 | iceoryx2 | 0.901 | 1095k | 7.6x |
| 8 | shared_memory | 0.1176 | 8496k | 1.0x |
| 9 | memory_mapped_file | 0.1189 | 8407k | 1.0x |
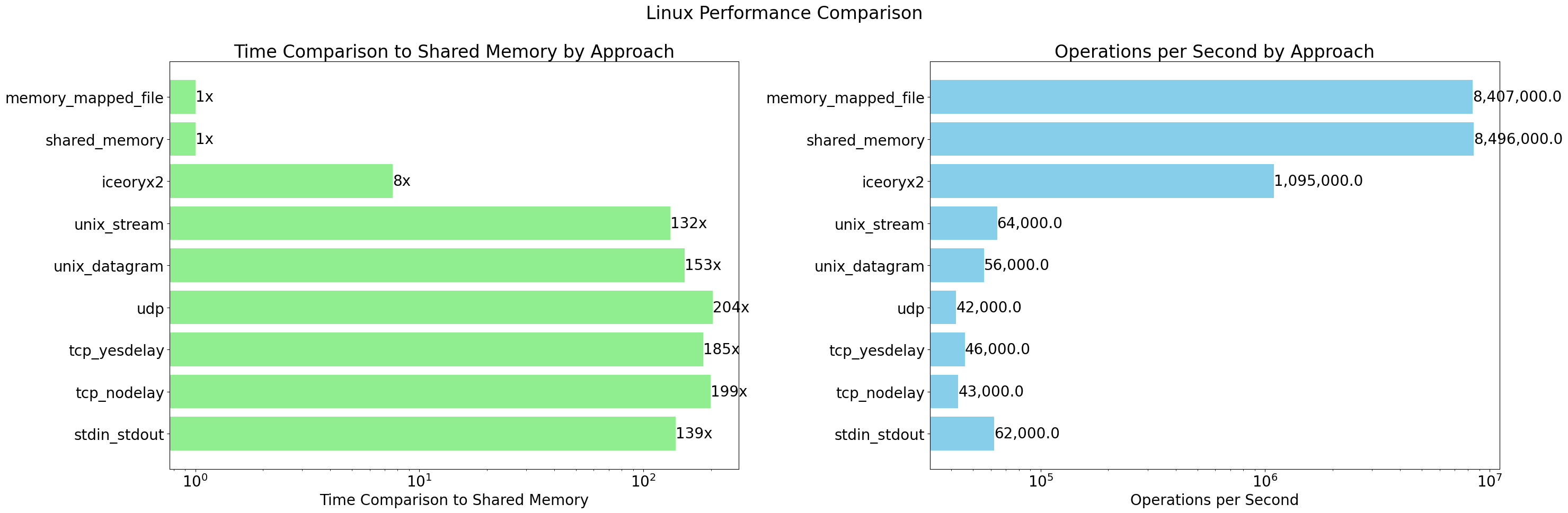
Here are some observations based on the ping-pong cycle performance:
- Shared memory and memory-mapped file approaches are consistently the fastest, with the lowest time per operation and highest operations per second.
- iceoryx2 performs remarkably well and is significantly faster than traditional IPC methods like pipes, sockets, and Unix domain sockets.
- Though there is no significant difference, UNIX domain sockets seem to perform better than IP sockets.
Varying Payloads Sizes
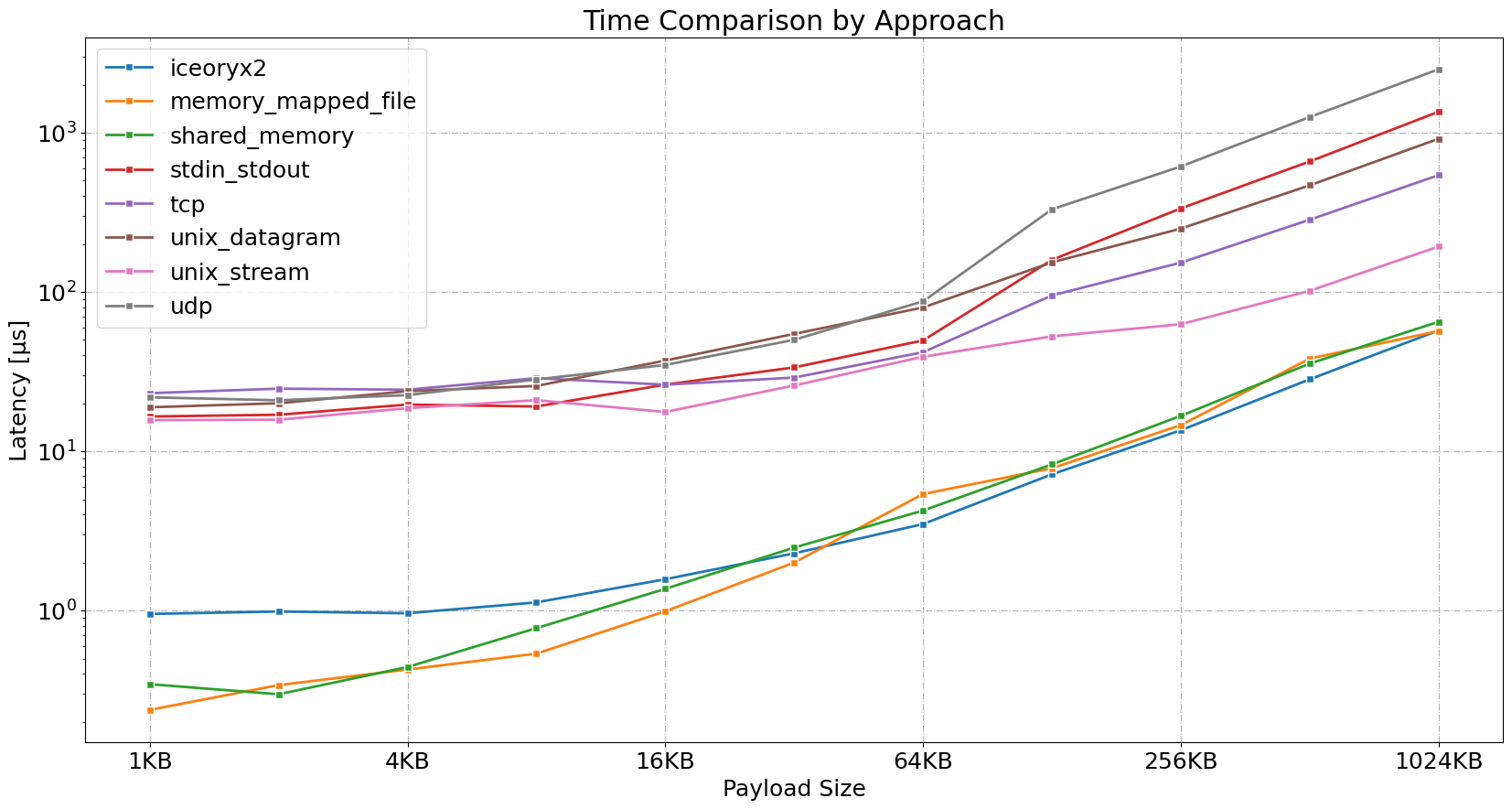
Time per Operation (in µs)
| Approach | 1KB | 2KB | 4KB | 8KB | 16KB | 32KB | 64KB | 128KB | 256KB | 512KB | 1024KB |
|---|---|---|---|---|---|---|---|---|---|---|---|
| iceoryx2 | 0.95 | 0.99 | 0.96 | 1.12 | 1.57 | 2.29 | 3.49 | 7.17 | 13.56 | 28.32 | 57.38 |
| memory_mapped_file | 0.24 | 0.34 | 0.43 | 0.54 | 0.99 | 2 | 5.39 | 7.82 | 14.6 | 38.18 | 56.92 |
| shared_memory | 0.34 | 0.3 | 0.44 | 0.78 | 1.37 | 2.48 | 4.24 | 8.28 | 16.7 | 35.53 | 65.09 |
| tcp | 23.17 | 24.73 | 24.36 | 28.79 | 26.19 | 29.03 | 41.92 | 95.19 | 153 | 284.5 | 541.9 |
| udp | 21.82 | 20.91 | 22.52 | 28.27 | 34.84 | 50.12 | 87.43 | 330.6 | 614.5 | 1256 | 2504 |
| unix_stream | 15.69 | 15.78 | 18.65 | 20.94 | 17.65 | 25.89 | 39.25 | 52.67 | 62.81 | 101.8 | 193.1 |
| unix_datagram | 18.9 | 20.03 | 23.85 | 25.72 | 37.13 | 54.6 | 79.98 | 153.6 | 250.2 | 467.9 | 917.1 |
| stdin_stdout | 16.54 | 16.96 | 19.65 | 19.11 | 26.23 | 33.63 | 49.66 | 159.3 | 335.2 | 660.5 | 1356 |
Ops per Sec (in k)
| Approach | 1KB | 2KB | 4KB | 8KB | 16KB | 32KB | 64KB | 128KB | 256KB | 512KB | 1024KB |
|---|---|---|---|---|---|---|---|---|---|---|---|
| iceoryx2 | 1070 | 1032 | 1061 | 907.4 | 648.9 | 444.5 | 288.4 | 136.7 | 73.91 | 35.36 | 18.11 |
| memory_mapped_file | 4303 | 2993 | 2390 | 1899 | 1028 | 506.8 | 251.1 | 130.9 | 68.43 | 34.86 | 18.04 |
| shared_memory | 4125 | 3428 | 2312 | 1312 | 744 | 409.7 | 236.5 | 120.6 | 60.09 | 30.55 | 15.44 |
| tcp | 45.38 | 45.05 | 44.01 | 30.05 | 40.63 | 37.13 | 27.07 | 10.77 | 6.84 | 3.43 | 1.8 |
| udp | 48.8 | 47.87 | 45.7 | 35.36 | 28.34 | 20.13 | 10.75 | 4.81 | 1.7 | 0.81 | 0.41 |
| unix_stream | 63.75 | 63.37 | 57.43 | 45.05 | 57.29 | 44.96 | 26.9 | 19.08 | 16.66 | 10.04 | 5.79 |
| unix_datagram | 54.6 | 51.61 | 50.32 | 38.87 | 29.98 | 16.81 | 13.3 | 6.23 | 3.83 | 2.14 | 1.09 |
| stdin_stdout | 61.1 | 60.06 | 58.43 | 52.77 | 43.82 | 32.82 | 21.35 | 5.83 | 2.88 | 1.58 | 0.74 |
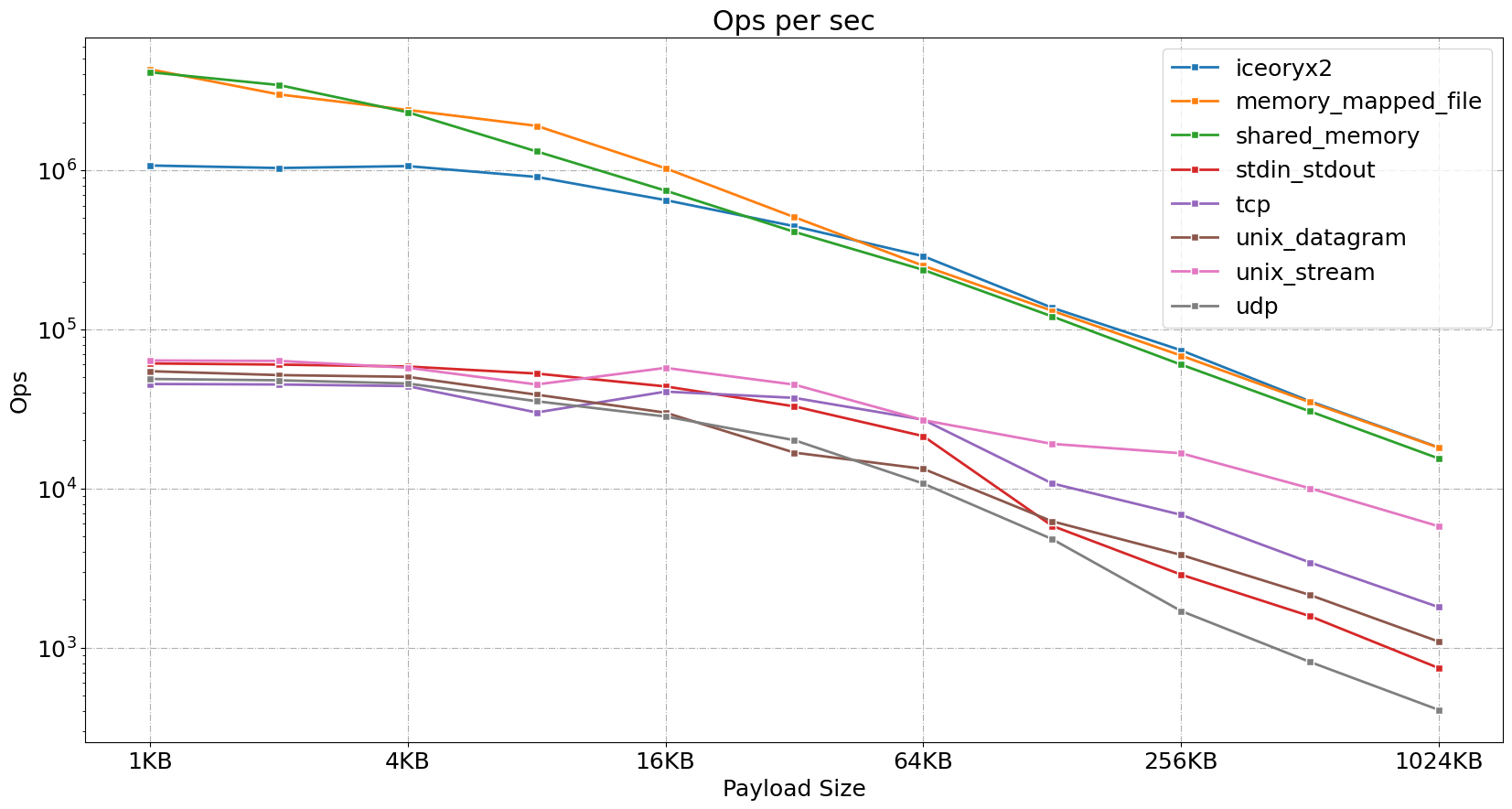
Here are some observations:
- Our first observation from the plot is the clear performance gap between memory based methods and traditional IPC methods.
- For smaller message sizes (1KB to 8KB), memory-mapped file and shared memory consistently outperform other methods, with the lowest time per operation and highest operations per second. iceoryx2 maintains a relatively flat latency profile up to 8KB.
- As message size increases, the performance gap between iceoryx2 and memory-mapped files/shared memory narrows significantly and performs comparably to memory-mapped files and shared memory.
- Within the traditional IPC methods, UNIX stream sockets have better performance across all message sizes.
- For payloads above 64KB, there is a significant performance degradation in UDP methods which could be due to the datagram size limitation.
- Memory-mapped file and shared memory show high throughput for all payload sizes.
- iceoryx2 maintains competitive throughput, especially for larger payloads.
- Traditional IPC methods show much lower throughput, with a steep decline as payload size increases.
Conclusion
iceoryx2 emerges as a very attractive option for high-performance inter-process communication. While it's not as fast as raw shared memory or memory-mapped files for smaller payloads, it abstracts away the complexities of manual synchronization required in shared memory and memory-mapped file approaches. iceoryx2 strikes an excellent balance between performance and developer-friendly abstractions, making it a compelling choice for high-performance IPC in Rust projects.
Special thanks to elBoberido and Abhirag for reviewing the post and suggesting improvements.
Full source code is available on Github, open for critiques and improvements 😊